TL;DR
Pick AWS Bedrock if you're already on AWS, need data residency, and want model choice across Nova, Claude, and Llama. Pick OpenAI for fastest prototyping and best out-of-the-box quality.
Cost gap is dramatic at scale: at 10K users doing 5 chats/day, Nova Lite on Bedrock runs ~$345/month vs ~$14,625/month on GPT-4o — Bedrock is 42x cheaper for that use case, 3.6x cheaper than GPT-4o-mini.
This trade-off doesn't apply if you need GPT-4-class reasoning quality on every request — the cheaper Nova/Claude tiers won't match it for hard tasks.
Why I Switched From OpenAI to AWS Bedrock
By Rohit Raj — Founding Engineer · 10+ yrs MVP shipping · LinkedIn
AWS Bedrock is the better choice for startups already running on AWS that need cost-efficient AI inference, data privacy controls, and the flexibility to switch between multiple model providers. OpenAI is the better choice for rapid prototyping, when you need the highest-quality model outputs, and when developer experience matters more than infrastructure control.
I was building MyFinancial — a privacy-focused financial advisory app for Indian users. The AI feature is a contextual chat advisor called Kira that answers questions like "Am I saving enough?" or "How can I optimize my taxes under 80C?"
I started with OpenAI's GPT-4. It worked great. The quality was excellent. Then I looked at the bill.
For a personal finance app handling sensitive income, tax, and investment data, I had three concerns:
- Cost — GPT-4 at \$30/1M input tokens was going to destroy my unit economics at scale
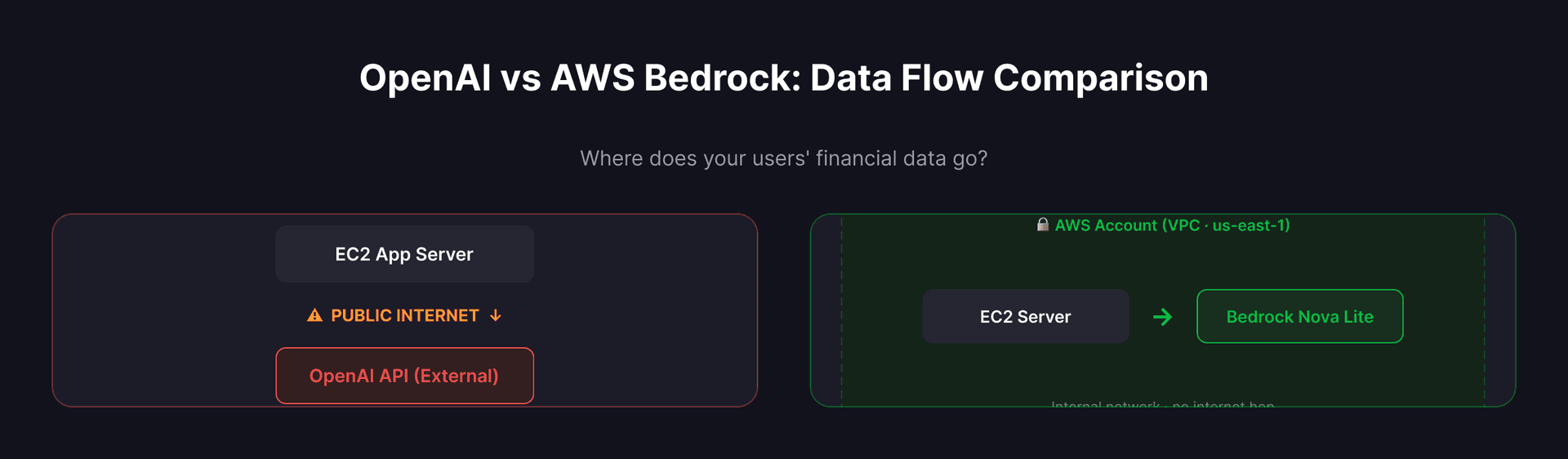
- Data residency — Financial data leaving my AWS infrastructure to hit OpenAI's API felt wrong
- Vendor lock-in — My entire AI feature depended on one company's API and pricing decisions
AWS Bedrock solved all three. The data stays within my AWS account, I get model choice (Nova, Claude, Llama), and the pricing is dramatically lower for my use case.
The Models: What You Actually Get
Here's what's available on each platform as of early 2026:
| Feature | OpenAI | AWS Bedrock |
|---|---|---|
| Top-tier model | GPT-4o | Claude Opus 4, Nova Pro |
| Mid-tier | GPT-4o-mini | Claude Sonnet, Nova Lite |
| Budget | GPT-3.5 Turbo | Nova Micro, Llama 3 |
| Embeddings | text-embedding-3-small | Titan Embeddings |
| Image generation | DALL-E 3 | Titan Image, Stable Diffusion |
| Model choice | OpenAI models only | 30+ models from multiple providers |
The killer feature of Bedrock is model choice. If Anthropic raises prices, I switch to Nova. If Meta releases Llama 4, I test it without changing my infrastructure. With OpenAI, you're locked into their models and their pricing.
For MyFinancial, I chose Amazon Nova Lite — it handles financial Q&A with good quality at a fraction of GPT-4's cost.
Real Cost Comparison From Production
Here's what I measured building the Kira financial advisor. Each chat interaction sends a system prompt (~800 tokens of financial context), user message, and up to 10 messages of conversation history. Responses are capped at 1024 tokens.
Typical request profile: - Input: ~1,500 tokens (system prompt + context + history + question) - Output: ~400 tokens (advisor response)
Cost per 1,000 chat interactions:
| Model | Input Cost | Output Cost | Total per 1K Chats | Monthly (10K users, 5 chats/day) |
|---|---|---|---|---|
| GPT-4o | \$3.75 | \$6.00 | \$9.75 | ~\$14,625 |
| GPT-4o-mini | \$0.23 | \$0.60 | \$0.83 | ~\$1,245 |
| Nova Lite (Bedrock) | \$0.09 | \$0.14 | \$0.23 | ~\$345 |
| Nova Micro (Bedrock) | \$0.05 | \$0.07 | \$0.12 | ~\$180 |
Nova Lite is 42x cheaper than GPT-4o and 3.6x cheaper than GPT-4o-mini for my use case. At 10K users doing 5 chats per day, that's \$345/month vs \$14,625/month. That difference is survival vs bankruptcy for a bootstrapped startup.
Note: These are on-demand prices. Bedrock also offers Provisioned Throughput for predictable costs at scale.
Common Mistakes When Managing AI Costs:
The biggest cost mistake is using your most expensive model for every request. Most applications have a distribution where eighty percent of queries are simple and ten to twenty percent require real reasoning. Route simple queries to Nova Micro or GPT-4o-mini and reserve expensive models for complex ones. Implement a complexity classifier — even a simple keyword-based router saves substantial money. The second mistake is not caching responses. If users frequently ask similar questions, cache the LLM response with a TTL. A Redis cache in front of your LLM endpoint can reduce API costs by thirty to fifty percent for many applications. The third mistake is sending too much context. Every token in your system prompt costs money on every request — audit your prompts regularly and remove instructions that do not improve output quality.
Is Nova Lite Good Enough for Production Applications?
Honest answer: it depends on your use case.
For MyFinancial's financial advisory chat, Nova Lite handles these well: - Explaining Indian tax concepts (80C, 80D, NPS, HRA) - Calculating savings rates and emergency fund recommendations - Comparing investment options (PPF vs ELSS vs FD) - Giving actionable, personalized advice based on user data
Where it struggles compared to GPT-4o: - Complex multi-step financial planning (e.g., "Plan my retirement considering inflation, tax regime changes, and two kids' education") - Nuanced tone — GPT-4o's responses feel more natural and empathetic - Edge cases with contradictory financial data
My approach: use Nova Lite for 90% of queries, escalate to Claude Sonnet on Bedrock for complex ones. The code already supports model switching:
This way, you get Nova Lite's cost efficiency for simple queries and Claude's reasoning power when it matters — all within Bedrock, no external API calls.
Which Platform Has Lower Latency?
I expected OpenAI to be faster since they operate dedicated inference infrastructure. In practice, from my EC2 instance in us-east-1:
| Model | Time to First Token | Total Response Time (400 tokens) |
|---|---|---|
| GPT-4o | ~800ms | ~3.2s |
| GPT-4o-mini | ~400ms | ~1.8s |
| Nova Lite (Bedrock) | ~300ms | ~1.5s |
| Nova Micro (Bedrock) | ~200ms | ~0.9s |
Bedrock is faster because the traffic stays within AWS's network. There's no internet hop to OpenAI's servers — my EC2 instance talks to Bedrock's endpoint in the same region. For a chat interface, that 300ms vs 800ms time-to-first-token is the difference between feeling instant and feeling sluggish.
Which Has a Better Developer Experience?
OpenAI wins on developer experience. Their SDK is cleaner, documentation is better, and the API is more intuitive.
OpenAI integration:
Bedrock integration (Java/Spring Boot):
Bedrock's API is lower-level. You build JSON request bodies manually, handle different response formats per model family, and deal with AWS SDK boilerplate. It's not hard — it's just more code.
The trade-off: OpenAI gives you a nicer SDK, Bedrock gives you infrastructure control. For a production app, I'll take infrastructure control every time.
What I Would Do Differently:
If I were starting the MyFinancial AI integration from scratch, I would build an abstraction layer over both Bedrock and OpenAI from day one. My current implementation has model-specific code paths that make switching providers harder than it should be. A clean interface with a common request and response format — regardless of whether the backend is Nova, Claude, or GPT — would let me A/B test models in production without touching business logic. I would also implement request-level cost tracking from the start. Knowing your cost per user per day lets you make pricing decisions with real data instead of estimates.
Privacy and Data Residency
This is where Bedrock wins outright for fintech.
With OpenAI, your users' financial data — income, expenses, tax details, investment portfolios — travels over the public internet to OpenAI's servers. Yes, they have a data processing agreement. Yes, they say they don't train on API data. But try explaining that to a compliance team.
With Bedrock: - Data never leaves your AWS account - You control the VPC, encryption keys, and access policies - CloudTrail logs every API call for audit - No data is used for model training — ever - You can run in specific AWS regions for data residency compliance
For MyFinancial, this was non-negotiable. Indian users' financial data staying within my AWS infrastructure isn't just good practice — it's a trust requirement.
When to Choose Which
Choose OpenAI when: - You're prototyping and want the fastest path to working AI - Quality is your top priority and cost is secondary - You need the latest cutting-edge models immediately - Your team is primarily Python and wants the best SDK experience
Choose AWS Bedrock when: - You're already on AWS (no new vendor relationship) - Cost efficiency matters at scale - Data privacy/residency is a requirement - You want model optionality (switch between Nova, Claude, Llama without code changes) - You need enterprise controls (IAM, VPC, CloudTrail)
My recommendation for Indian startups: Start with OpenAI for your prototype. Switch to Bedrock before you hit 1,000 users. The cost difference at scale will pay for the migration effort many times over.
Key Takeaways
- Bedrock is 40x cheaper than GPT-4o for production workloads — the math isn't close
- Latency is better on Bedrock when your app runs on AWS — no internet hop
- Nova Lite handles 90% of use cases — save Claude/GPT-4 for the hard 10%
- Data residency is a real differentiator — especially for fintech handling sensitive financial data
- OpenAI has better DX — Bedrock requires more boilerplate but gives you more control
- Model optionality is Bedrock's superpower — you're not locked into one provider's pricing decisions
Frequently Asked Questions
Q: Can I use both OpenAI and AWS Bedrock in the same application?
Yes, and this is a common production pattern. Use OpenAI for prototyping and user-facing features where quality matters most, and Bedrock for high-volume background tasks where cost efficiency is critical. For example, you might use GPT-4o for customer support chat where response quality directly affects user satisfaction, and Nova Micro on Bedrock for batch processing tasks like summarizing thousands of documents overnight. The key is building a provider-agnostic abstraction layer so your application code does not need to know which backend is handling each request.
Q: How does AWS Bedrock handle rate limits compared to OpenAI?
Bedrock uses a different model. Instead of rate limits per API key, Bedrock provides account-level quotas measured in tokens per minute per model. You can request quota increases through the AWS console, and for predictable workloads you can purchase Provisioned Throughput for guaranteed capacity. OpenAI uses tier-based rate limits that increase as you spend more. For bursty workloads, Bedrock's quota model is more predictable. For gradual scaling, OpenAI's tier system is simpler to manage. Both platforms queue excess requests rather than dropping them outright.
Q: Is it hard to migrate from OpenAI to AWS Bedrock?
The migration is straightforward if you planned for it. The main work is adapting your request and response format — OpenAI and Bedrock use different JSON structures for chat completions. Prompt text usually transfers without changes, but you should evaluate output quality for your specific use case because different models respond differently to the same prompt. Budget one to two weeks for the migration including prompt tuning and quality validation. If you build a provider abstraction layer from the start, the migration reduces to implementing a new adapter class.
Q: Does Bedrock support streaming responses for chat interfaces?
Yes. Bedrock supports streaming via the InvokeModelWithResponseStream API. You receive tokens as they are generated, which is essential for chat interfaces where users expect to see the response appearing in real time. The implementation requires handling Server-Sent Events from the Bedrock endpoint and forwarding them to your frontend via WebSockets or SSE. OpenAI's streaming implementation is slightly simpler to set up because their SDK handles the event parsing automatically, but both achieve the same end result for the user.
Q: What happens to my data when I use Bedrock versus OpenAI?
With Bedrock, your data stays within your AWS account and is never used for model training. AWS provides this guarantee contractually. You control encryption keys via KMS, network access via VPC endpoints, and audit logging via CloudTrail. With OpenAI's API, data is not used for training by default since March 2023, but the data does travel to OpenAI's infrastructure over the public internet. For regulated industries like healthcare and finance, Bedrock's data residency guarantees are often a compliance requirement, not just a preference.
Ship Your AI Product on the Right Infrastructure — Without the 6-Month Decision Loop
If you are picking between AWS Bedrock and OpenAI for an MVP shipping in the next 6 weeks, the infrastructure debate is not the bottleneck — the integration speed is. I ship founder MVPs end-to-end in 6 weeks: AI integration (any provider above + the routing layer), backend, frontend, India-billing-friendly deployment.
If you want the cost-and-latency math redone for your specific workload — drop a note with expected RPS and prompt size and I will run the numbers against your real prompt before you commit to a vendor.
→ Hire me to ship your 6-week MVP (fixed price, fixed scope, full GitHub from commit one) → Or have me build the AI chatbot piece directly (WhatsApp + LLM + Hinglish) → Or hire me as a founding engineer for the long haul (sprint or retainer, no equity ask)
Related notes: OpenAI vs Claude vs Gemini API cost for India MVP 2026 for the direct API comparison, How to add AI to your existing business app for retrofit patterns, and Build an AI chatbot for WhatsApp Business for the production deployment playbook.